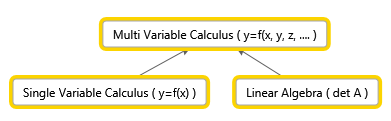
Introduction
During the two periods (from January), I’ve been working with with an interesting branch of mathematics – Multi Variable Calculus. Besides, I was studying Linear Algebra (see my other post) and Numerical Methods. Since I’m not actually supposed to study it in year 1, it was quite difficult when I needed knowledge of Linear Algebra to be able to understand certain concepts. In addition, there were clashes with other lectures and practice sessions, so I was effectively left with the course literature and other resources. This put me into a situation where I had to obtain the knowledge on my own and ensure that I understood the concepts. A friend of my (who took this course also) was sitting in the library and used other books that were available. My strategy was to use the original book in addition to the resources available online (such as other literature, videos, and Math SE). I think both strategies were really helpful in the study of Multi Variable Calculus. Here’s one thing I thought about two months after the course start:
$$ \displaystyle \underset{{Time\to \infty }}{\mathop{{\lim }}}\,Calculus=Physics$$
This is the connection between the subjects:
Spaces (3 to n space)
It’s quite convenient to translate real world problems into mathematical models, manipulate the data and interpret the result in a real world context. Since we live in a 3 dimensional world (at least, that’s the way many of us interpret it), many might already be familiar with \(x,y,z\) coordinate system that allows us to express location of any object. But, if we were able to go from having things expressed in \(2\)d to \(3\)d, why not just go directly to \(4\) or even \(n\) space? Suddenly, we need to ensure that our definitions of concepts such as distance, neighborhood are clear and make sense even when we leave \(3\) space.
Let’s look at neighborhood. If we simply think about a line with numbers, we could say that neighbors to a number \( p\) are numbers in the interval \((p-r,p+r)\). So, if we set \(r=2\) and choose \(p\) to be \(3\), the interval is \((1,5)\). So, \(1,2,4,5\) are some of the neighbors to \(3\) at a distance \(r\). Now, you might wonder why we look at the neighborhood. That’s simply to illustrate how things change when we add another dimension. Imagine that we are asked about the neighborhood to a point \(p\) in \( 2\) space instead. Instead of a line, we get a disk with a radius \(r\) centered at point \(p\). In \(3\) space, it’s a ball centered at \(p\) of radius \( r\). The same trend will be observed when we started to look at the domain. For simple functions, the domain is a set of points on a line. For two variables, it is two-dimensional object and so on.
Cylindrical Coordinates
In single variable calculus, the polar coordinates might ring a bell. Cylindrical coordinates are quite similar. We basically perform the following substitution:
$$\left\{ \begin{gathered}
x = r\cos \theta \hfill \\
y = r\sin \theta \hfill \\
z = z \hfill \\
\end{gathered} \right.$$
The convention is that \(r\ge 0\) and that \(0 \le \theta \le 2\pi\). You might ask why we would need such coordinates? I had a similar question when I confronted them. They were more annoying than useful at the first sight (but spherical coordinates were even worse). However, once I started to deal with integrals with “strange” domains, they were a great relief. It will also be useful to know that the volume element is:
$$ \displaystyle dV=rdrd\theta dz$$
Spherical Coordinates
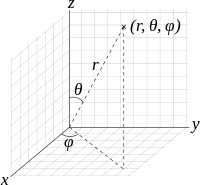
Spherical coordinates, as cylindrical coordinates, are based on a substitution that contains trigonometric functions. In this case, the substitution is:
$$ \displaystyle \left\{ \begin{array}{l}x=R\sin \phi \cos \theta \\y=R\sin \phi \sin \theta \\z=R\cos \phi \end{array} \right.$$
The convention is that \(\displaystyle R\ge 0,\quad 0\le \phi \le \pi ,\quad 0\le \theta \le 2\pi \). The volume element that proves to be useful later is \(\displaystyle dV={{R}^{2}}\sin \phi dRd\phi d\theta \).
Vector Functions
In many physics scenarios that appear in high school textbooks, problems are reduced two one/two dimensions. However, all of us know that the world has both a width, a breadth and a height. So, it can be useful to represent objects using three coordinates. If we disregard relativity for a moment, let’s say that the position of a particle is determined by time \(t\). In other words,
$$ \displaystyle \left\{ \begin{array}{l}x=x(t),\quad y=y(t),\quad z=z(t)\\\vec{r}=(x(t),y(t),z(t))\end{array} \right.$$
So, you give me a time \(t\) and I will be able to tell you where the particle is. In the same manner, we can express velocity and acceleration. That is,
$$ \displaystyle \vec{v}=\frac{d\vec{r}}{dt}=\left( \frac{dx}{dt},\frac{dy}{dt},\frac{dz}{dt} \right),\qquad \vec{a}=\frac{{{d}^{2}}\vec{r}}{d{{t}^{2}}}=\left( \frac{{{d}^{2}}x}{d{{t}^{2}}},\frac{{{d}^{2}}y}{d{{t}^{2}}},\frac{{{d}^{2}}z}{d{{t}^{2}}} \right)$$
Both velocity and acceleration have a magnitude and a direction, whereas speed has a magnitude only. However, in practice, we hear people use velocity and speed interchangeably. Anyway, given a velocity vector, it’s quite easy to find the speed, namely by taking the (euclidean) norm. That is,
$$ \displaystyle v=||\vec{v}||=\left\| \frac{d\vec{r}}{dt} \right\|={{\left( \frac{dx}{dt} \right)}^{2}}+{{\left( \frac{dy}{dt} \right)}^{2}}+{{\left( \frac{dz}{dt} \right)}^{2}}$$
Example: An object is moving to the right along the plane \(y=x^2\) with constant speed \(v=5\). Find \(\vec v\) at $(1,1)$.
Solution: We simply need to express the movement in the plane as a vector, so since we \(y=x^2, \quad \vec r =(x,x^2)\). By taking the derivative of \(\vec r\), we get:
$$ \displaystyle \vec{v}=\frac{d\vec{r}}{dt}=\left( \frac{dx}{dt},2x\frac{dx}{dt} \right)=\frac{dx}{dt}(1,2x)$$
(do you recognize implicit differentiation? )We know that the speed is \(5\), and that
$$ \displaystyle v=||\vec{v}||=\left| \frac{dx}{dt} \right|\sqrt{1+{{(2x)}^{2}}}=5$$
This implies that
$$ \displaystyle \frac{dx}{dt}=\frac{5}{\sqrt{1+{{(2x)}^{2}}}}=(\text{at point (1,1)})=\sqrt{5}$$
Therefore,
$$ \displaystyle \vec{v}=\frac{dx}{dt}(1,2x)=\sqrt{5}(1,2)$$
NB: Keep in mind that the \(dx/dt\) term is not a vector, it’s a scalar.
Rules for Differentiation
They work in a similar way as in single variable calculus. There won’t be any nasty expressions, even if dot/cross product is involved. A word of warning: differentiation of vector functions only works if the basis vectors do not depend on the variable of differentiation. An example of the product rule with cross product: \(\displaystyle \frac{d}{dt}(\vec{u}\times \vec{v})=\vec{u}’\vec{v}+\vec{u}\vec{v}’\).
Arc Length
After a minute of though, we quickly realize that the arc length is given by
$$ \displaystyle s=\int_{a}^{b}{\left| \frac{d\vec{r}}{dt} \right|dt=\int_{a}^{b}{|\vec{v}(t)|dt}}=\int_{a}^{b}{v(t)dt}$$
We might recall that when dealing with arc length of functions of one variable, the arc element (do you see the connection between the surface element?) happens to be \(\displaystyle ds=\sqrt{1+{{\left( \frac{dy}{dx} \right)}^{2}}}dx\), which we can obtain by rearranging \(\displaystyle {{(ds)}^{2}}={{(dx)}^{2}}+{{(dy)}^{2}}\) (Pythagoras’s theorem).
Functions of Several Variables
Before we move on to to 3 space, let’s look at one way we can get an understanding for 3 space using 2 space.
Level Curves
Suppose you are walking in a forest and have a map at your disposal. Even if the map is two dimensional, you are still able to apply it to the thee dimensional world. When you see a mountain, it is going to be expressed as a series of circles that indicate the “height”. The same can be done for functions of two variables. Say we have a paraboloid \(\displaystyle {{z}}={{x}^{2}}+{{y}^{2}}\). To find the level curves, we replace \(z\) with a constant \(c\), i.e. \(\displaystyle c={{x}^{2}}+{{y}^{2}}\). Now, this should be quite familiar to many, as it is the equation of a circle. By changing the \(c\), we are actually changing the radius of the circle.
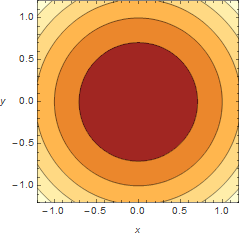
Contour plot
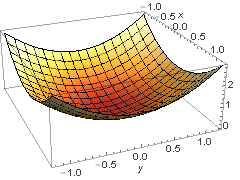
The 3d representation
It’s difficult to get a picture of the 4d world, but at least, using the same principle, it should be possible to gain an understanding.
Derivatives (Vector Calculus)
In Multi Variable Calculus, there isn’t just one operator that we can refer to as derivative. There are three of them:
- grad – \(\displaystyle \nabla f(x,y,z)=\left( {\frac{{\partial f}}{{\partial x}},\frac{{\partial f}}{{\partial y}},\frac{{\partial f}}{{\partial z}}} \right)\qquad \mathbb{R}\to {{\mathbb{R}}^{3}}\)
- div – \(\displaystyle \nabla \cdot \vec{F}=\frac{{\partial f}}{{\partial x}}+\frac{{\partial f}}{{\partial y}}+\frac{{\partial f}}{{\partial z}}\qquad {{\mathbb{R}}^{3}}\to \mathbb{R}\)
- curl – \(\displaystyle \nabla \times \vec{F}=\left( {\begin{array}{*{20}{c}} {\vec{i}} & {\vec{j}} & {\vec{k}} \\ {\frac{\partial }{{\partial x}}} & {\frac{\partial }{{\partial y}}} & {\frac{\partial }{{\partial z}}} \\ {{{F}_{1}}} & {{{F}_{2}}} & {{{F}_{3}}} \end{array}} \right)\qquad {{\mathbb{R}}^{3}}\to {{\mathbb{R}}^{3}}\)
I think we might conclude that all of them use the same symbol (nabla). It’s quite interesting to point out that a lot of information is stored in the notation used. (ToK: Discuss the importance of conveying knowledge through notation)
Gradient
A gradient vector of a function is the normal vector of the function. The norm of a gradient vector tells the maximum rate of increase. The function at \((a,b)\) increases most rapidly in the direction of the gradient vector at point \((a,b)\).
Divergence
Divergence is a measure of the rate at which the field diverges, i.e. spreads away from a point \(p\). I’ve observed that the net total flux of a solenoidal vector field ( \(div \vec F =0\)) is zero. This can be proved by a converting the flux integral into a triple integral using Divergence (Gauss) theorem.
Curl
Curl (rot in Swedish) is a measure of rotation, or differently phrased, how much a vector field swirls around a point.
Identities
Get ready, this will be a long list:
$$ \displaystyle \begin{array}{l}\nabla (\phi \psi )=\phi \nabla \psi +\psi \nabla \phi \\\nabla \cdot (\phi \vec{F})=(\nabla \phi )\cdot \vec{F}+\phi (\nabla \cdot \vec{F})\\\nabla \times (\phi \vec{F})=(\nabla \phi )\times \vec{F}+\phi (\nabla \times \vec{F})\\\nabla \cdot (\vec{F}\times \vec{G})=(\nabla \times \vec{F})\cdot \vec{G}-\vec{F}(\nabla \times \vec{G})\\\nabla \times (\vec{F}\times \vec{G})=(\nabla \cdot \vec{G})\vec{F}+(\vec{G}\cdot \nabla )\vec{F}-(\nabla \cdot \vec{F})\vec{G}-(\vec{F}\cdot \nabla )\vec{G}\\\nabla (\vec{F}\cdot \vec{G})=\vec{F}\times (\nabla \times \vec{G})+\vec{F}\times (\vec{G}\times \nabla )+(\nabla \cdot \vec{F})\vec{G}-(\vec{G}\cdot \nabla )\vec{F}\\\nabla \cdot (\nabla \times \vec{F})=\operatorname{div}curl\\\end{array}$$
Sometimes, it’s clear that they follow the same pattern as the usual product rule in single variable calculus. Some have to be derived brute force. Great that we don’t need to do it and instead can use them to build on top of this knowledge!
Directional Derivative
By looking at the gradient, we might have realized that a normal to surface is no longer a line (as is the case in single variable calculus), but rather a plane, or even a body of some sort. For functions with one variable, we only have one \(\displaystyle \frac{dy}{dx}\), while the gradient contains three “derivatives”, \(\displaystyle \left( \frac{\partial f}{\partial x},\frac{\partial f}{\partial y},\frac{\partial f}{\partial z} \right)\).
Now, back to directional derivatives. Really what it means is the rate of change of \(f(x,y)\) at \((a,b)\) in the direction of a vector \(\vec u\). It’s obtained by:
$$\displaystyle \frac{{\vec{u}}}{||u||}\nabla f(a,b)$$
The cool thing is that, in contrast to the gradient, the directional derivative actually gives us a value rather than a vector (set of values). Since the gradient points in the direction of the maximal increase, it can be useful to set it to be \(\vec u\).
Keep in mind that \(\vec u\) has to be a unit vector, otherwise, we will solve a different problem, namely, the rate of change of \(f(x,y)\) at \((a,b)\) as measured by a moving observer (through \((a,b)\)) with a velocity \(\vec v\).
Taylor Polynomials
From single variable calculus, most of us will recognize Taylor series/polynomials. It’s a way to approximate functions close to a point by a polynomial. It’s quite similar to linearization where we could use the information we have about the slope and the function value in one point to predict the points in its neighborhood. By the way, in MVC, linearization formula looks like:
$$ \displaystyle f(x,y)\approx L(x,y)=f(a,b)+{{f}_{1}}(a,b)(x-a)+{{f}_{2}}(a,b)(y-b)$$
Since we don’t really have the concept of a tangent line, we have a tangent plane instead (the gradient is a set of derivatives, not just one). That’s why we have one \(f\) with subscript 1 and another with subscript 2. Don’t get confused by my notation; the subscript indicates the index of the variable of integration, i.e. \(\displaystyle {{f}_{1}}={{f}_{x}}\).
The general Taylor polynomial is given by
$$ \displaystyle f(\vec{a}+\vec{h})=\sum\limits_{{i=0}}^{m}{{\frac{{{{{(h\cdot \nabla )}}^{j}}f(\vec{a})}}{{j!}}}}+\frac{{{{{(h\cdot \nabla )}}^{{(m+1)}}}f(\vec{a}+\theta \vec{h})}}{{(m+1)!}}$$
or equivalently,
$$ \displaystyle f(\vec{a}+\vec{h})=f(\vec{a})+h\cdot \nabla f(\vec{a})+\frac{{{{{(h\cdot \nabla )}}^{2}}f(\vec{a})}}{{2!}}+\ldots +\frac{{{{{(h\cdot \nabla )}}^{m}}f(\vec{a})}}{{m!}}+\frac{{{{{(h\cdot \nabla )}}^{{m+1}}}f(\vec{a}+\theta \vec{h})}}{{(m+1)!}}$$
The questions I’ve been working with rarely required a polynomial of the third degree (if at all). Assuming that this will be the case during the exam, there’s a neat formula to remeber the the second order Taylor polynomial using a Hessian matrix (will describe under Extreme Value), namely,
$$ \displaystyle f(\vec{a}+\vec{h})=f(\vec{a})+h\cdot \nabla f(\vec{a})+\frac{1}{{2!}}{{\vec{h}}^{T}}\mathbf{H}\vec{h}$$
Exteme Values
Gradient(1st derivative test)
Gradient is a way to find the critical points of a function that occur at \(\displaystyle \nabla g(x,y)=0\).
Hessian (2nd derivative test)
The Hessian matrix is a way to find whether a point is a maximum, minimum or a saddle point. There are four cases:
- Positive definite -> local minimum
- Negative definite -> local maximum
- Indefinite -> saddle point
- Other -> can’t tell.
Lagrange Multipliers
This might sound complex, but it’s all really about finding a maximum or minimum value of a function subjected to a constraint. There are two ways to think about it. In both ways, let \(f(x,b)\) be a function subjected to the constrain \(g(x,y)=0\). Then, we can work with a different function, that is, the Lagrange function: \(\displaystyle L(x,y,z)=f(x,y)+\lambda g(x,y)\) and attempt to find its critical points. The way I think is better is to think about it though is by considering the fact that we want the gradient of the function to be parallel to the gradient of the constraint, i.e. \(\displaystyle \nabla f(x,y)=\lambda \nabla g(x,y)\). Then, we simply need to solve the system of linear equations.
Integrals
In high school, many of us have been taught how to solve $$\int {f(x)dx} $$
Some of the techniques that might ring a bell are partial fractions, substitutions, etc. It might have been mentioned that integration is a way to find the area (depending on the definition) under the graph of a function \(f(x)\). When I confronted MVC, I start to ask myself what each integral really represents, because it’s no longer possible to simply try to evaluate an integral.
Simple Integrals
By simple integrals, I mean \(\displaystyle \iint\limits_{D}{{f(x,y)dA}}\) or \(\displaystyle \iiint\limits_{D}{{f(x,y,z)dV}}\). Here’s an interesting thing that can be observed. \(\displaystyle \int\limits_{D}{{dx}}\) is the length of the domain (a unit length), \(\displaystyle \iint\limits_{D}{{dxdy}}\) represents the area of the domin (squared units), and finally \(\displaystyle \iiint\limits_{D}{{dxdydz}}\) represents the volume of the domain (cube units). If we multiply by a function (inside the integral), we shift the definitions. Instead, the single integral will represent an area, the double integral will be a volume and the triple integral will be ….? Yeah, now we get into things that are quite hard to visualize. Basically, we would get a hyper volume.
Solving Simple Integrals
To solve simple integrals, we can, in most cases, use iteration. I’m not going to get into details, but basically, it’s a way to turn a double/triple integral into single integrals. However, at certain points, the domain we get might be very complicated. As an example, here’s a really simple iteration:
$$ \displaystyle \iint\limits_{\begin{smallmatrix}
0\le x\le 1 \\
0\le y\le 2
\end{smallmatrix}}{{xydxdy=\int\limits_{0}^{2}{{ydy\int\limits_{0}^{1}{{xdx=\{something\}}}}}}}$$
But, suppose we have a different case:
$$ \displaystyle \iint\limits_{{{{x}^{2}}+{{y}^{2}}\le 1}}{{{{x}^{2}}dxdy}}$$
This is not as obvious. However, we can perform a substitution (polar coordinates) to get \(\displaystyle \iint\limits_{{{{x}^{2}}+{{y}^{2}}\le 1}}{{{{x}^{2}}dxdy}}=\int\limits_{0}^{{2\pi }}{{\int\limits_{0}^{1}{{{{r}^{2}}{{{\cos }}^{2}}\theta drd\theta }}}}\). Then, it’s quite easy to find the value. The important conclusion is that \(\displaystyle dA=dxdy=rdrd\theta\). We can find the area/volume element by inserting into a Jacobian matrix, \(\displaystyle \frac{{\partial (x,y)}}{{\partial (r,\theta )}}\).
Advanced Integrals?
The title is, to some extent, misleading, as the integrals aren’t that difficult but it might be harder to conceptualize them. All of the integrals I’m going to describe require understanding of vector fields, which will be described shortly below.
Fields and Integrals
This is the continuation of the previous section with focus on “advanced integrals”.
Fields
My understanding of fields is as a way to describe motion. We can, for instance, have a velocity field, which describes velocity at any given point. So, you give me a location and I will tell you the direction of the velocity vector at that point. In order to illustrate vector fields, we can try to find the field lines. Here’s how:
$$ \displaystyle \frac{{dx}}{{{{F}_{1}}(x,y,z)}}=\frac{{dy}}{{{{F}_{2}}(x,y,z)}}=\frac{{dz}}{{{{F}_{3}}(x,y,z)}}$$
The subscript, in this case, does not denote the partial derivative but rather the component of the vector field. By solving this differential equation, we are able to express the the field lines. For example, if the velocity field is \(\displaystyle \vec{v}=(-y,x)\), we would get \(\displaystyle \frac{{dx}}{{-y}}=\frac{{dy}}{x}\quad \Rightarrow \quad {{x}^{2}}+{{y}^{2}}=c\). Thus, the field lines will look like circles.
In addition, it’s important to keep in mind that there are both scalar fields and vector fields.
Physics and Fields
When I started to study this particular section, I thought it was great that I took physics higher level in high school. Concepts such as conservative fields, equipotential surfaces, etc., made more sense because of the prior knowledge. The cool thing about conservative fields occurs when we want to find the value of a line integral (described later). Since the definition of a conservative field that has the property \(\displaystyle \vec{F}=\nabla \phi \), we can make an attempt to find the potential function \(\phi\) instead and insert the desired starting and ending point. In conclusion, the conservative fields lead to path independence, i.e. it does not matter how we arrive at the end point.
Line Integrals
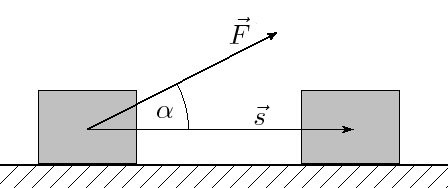
From (https://commons.wikimedia.org/wiki/File:Mehaaniline_t%C3%B6%C3%B6.png?uselang=ru)
Line integrals are pretty much based on the idea of finding the work (in physics). As we all know, work=force*distance. But, it’s only the x component we need, thus, \(\displaystyle dW=|\vec{F}|\cos \theta ds\). This is the same as \(\displaystyle dW=\vec{F}\cdot \hat{T}ds\). We know from single variable calculus that the tangent points in the direction of the derivative, so, \(\displaystyle \hat{T}=\frac{{d\vec{r}}}{{ds}}\). Integrating this, we get: \(\displaystyle \int\limits_{C}{{\vec{F}\cdot d\vec{r}}}\).
A good strategy is to parametrize the curve when evaluating a line integral.
Surface Integrals
Surface integrals are a step further than a line integral, analogous to the double integral that is a step further than a single integral.
$$ \displaystyle \iint\limits_{S}{fdS=}\iint\limits_{S}{f(\vec{r}(u,v))\left| \frac{\partial \vec{r}}{\partial u}\times \frac{\partial \vec{r}}{\partial u} \right|dudv=}\iint\limits_{S}{f(\vec{r}(u,v))\left| \frac{\partial (x,y,z)}{\partial (u,v)} \right|dudv}$$
As they are not quite the same as double integrals, we have to add a “term”, which can be though of as a conversion factor. In a double integral, we can think of the procedure as adding small rectangles and when we deal with surface integrals, we are essentially attempting the same thing, but a surface can be tilted and bent. So, we are projecting the it onto the \(xy\) plane for instance. There’s going to be a slight difference between the area of the rectangle and the area of the surface, which we compensate using the conversion factor.
Flux Integrals
One of the parts of physics in high school that I found quite hard was flux. However, it’s not really that hard after a half a year of work! A flux integral is essentially a surface integral with some additional terms. Imagine we have a field and we put a surface of some kind in front of that field. If we put it perpendicular to the field (the normal of the surface will be parallel), everything will pass through. In contrast, if the surface is parallel to the surface (the normal vector is perpendicular), nothing will get through. We can relate to the dot product that exhibits similar properties \(\displaystyle a\cdot b=0\quad \Leftrightarrow \quad a\bot b\). Below is a flux integral:
$$ \displaystyle \begin{array}{l}\iint\limits_{S}{\vec{F}\cdot \hat{N}dS=}\iint\limits_{S}{\vec{F}\cdot \left| \frac{\partial (x,y,z)}{\partial (u,v)} \right|dudv}\\\end{array}$$
Connecting Integrals
There are three important theorems in multi variable calculus that connect different kinds of integrals: Green’s theorem, Divergence theorem, and finally Stokes’s theorem.
Green’s Theorem (line = double)
If we have a closed curve, we are able to convert a line integral into a double integral and vice versa, i.e.
$$ \displaystyle \oint\limits_{C}{\vec F\cdot d\vec{r}=\iint\limits_{R}{\left( \frac{\partial {{{\vec{F}}}_{2}}}{\partial x}-\frac{\partial {{{\vec{F}}}_{1}}}{\partial y} \right)}}dA$$
Divergence (Gauss) Theorem (surface = tripple)
If we have a closed surface with a unit normal vector \(\hat N\), we are able to go from a surface integral to a triple (simple) integral, and vice versa.
$$ \displaystyle \iiint\limits_{D}{div\vec{F}dV=\mathop{{\int\!\!\!\!\!\int}\mkern-21mu \bigcirc}\limits_C
\vec{F}\cdot \hat{N}dS }$$
Stokes’s Theorem (line = surface)
It’s a way to convert a line integral into a surface integral and vice versa.
$$ \displaystyle \oint\limits_{C}{\vec{F}\cdot d\vec{r}=\iint\limits_{R}{curl\vec{F}\cdot \hat{N}dS}}$$
Physics Applications (other applications)
Apart from those already mentioned, triple integrals can for instance be used to find the center of mass and the mass, i.e.
- The x coordinate of the center of mas is given by \(\frac{\iiint_D x dV}{\iiint_D dV}\)
- The density function \(\rho\) can be integrated to get the mass \(\iiint_D\rho(x,y,z) dV\)
We might ask why we need functions of several variables. Well, the world has many relations where one value depends on several variables. For example, Finance. For example, Riksbanken probably has a mathematical model (I really hope!) of the way interest should be calculated, which can depend on both the interest in European counties, price of houses, etc. There are many variables, which will lead to situations where MVC knowledge will be useful.
Conclusion
I must say that each time I complete a course in mathematics, I get a new picture of the world. In the case of MVC, the great thing in my mind is the combination of single variable calculus and linear algebra (and of course, Physics). I guess it’s like philosophy, it makes you think in different ways.
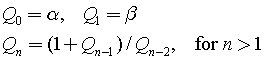
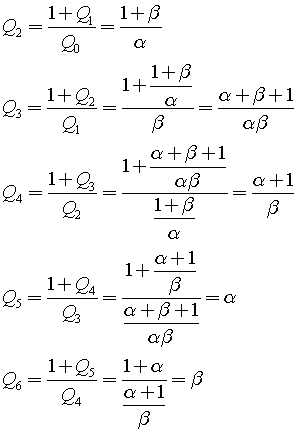
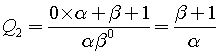
 .
.